

★悩み★
・SparkでKubernetesの永続ボリューム(PV/PVC)を使う手順を知りたいな。
・PySpark(Python on Spark)でKubernetesの永続ボリュームを使いたい。
・Apache SparkでKubernetesの「永続ボリューム(PV/PVC)」を使う利点は?
こういった「悩み」に答えます。
★本記事の内容★
① SparkでKubernetesの「永続ボリューム(PV/PVC)」を使う利点をご紹介
② Spark on Kubernetesで永続ボリューム(PV/PVC)を使う為の準備をご紹介
③ Spark on Kubernetesで永続ボリューム(PV/PVC)を使う手順をご紹介
これからご紹介する「Spark on Kubernetesで永続ボリューム(PV/PVC)を使う手順」を実践したことで、3時間以内で「PySparkアプリで集計したデータをKubernetesの永続ボリューム(PV/PVC)に保存」できました。
記事の前半では「SparkでKubernetesの永続ボリューム(PV/PVC)を使う利点」を解説しつつ、記事の後半では「Spark on Kubernetesで永続ボリューム(PV/PVC)を使う手順」を紹介します。
この記事を読み終えることで、「Apache SparkでKubernetesの永続ボリューム(PV/PVC)を使える」状態になります。
ちなみに、「Kubernetesを体系的に学習したい」方には、以下の記事がお勧めです。



SparkでKubernetesの永続ボリューム(PV/PVC)を使う利点

「SparkでKubernetesの永続ボリューム(PV/PVC)を使う利点」に関してご紹介します。
★SparkでKubernetesの永続ボリュームを使う利点に関するご紹介事項★
・Kubernetesの永続ボリューム(PV/PVC)とは何か?
・SparkでKubernetesの永続ボリューム(PV/PVC)を使う利点
以降で、上記「SparkでKubernetesの永続ボリュームを使う利点に関するご紹介事項」の各項目に関してご説明します。
Kubernetesの永続ボリューム(PV/PVC)とは何か?
「Kubernetesの永続ボリューム(PV/PVC)とは何か?」に関しては、以下の記事をご覧ください。

上記記事では、Kubernetesにおける「永続ボリューム/PV/PVC」の違いやできることを図で解説しています。
以上が、「Kubernetesの永続ボリューム(PV/PVC)とは何か?」となります。
SparkでKubernetesの永続ボリューム(PV/PVC)を使う利点
「SparkでKubernetesの永続ボリューム(PV/PVC)を使う利点」に関してご説明します。
Apache SparkでKubernetesの永続ボリューム(PV/PVC)を使うことで、どのような恩恵を得られるかに関して簡単に説明しますね。
結論から述べますと、「Kubernetes上で実行したPySparkアプリ(Pythonで実装したSparkアプリ)で集計したデータなどをPod終了後でも参照可能」となります。以降で、上記に関して紐解いていきますね。
Kubernetes上で実行したPySparkアプリ(Pythonで実装したSparkアプリ)は、Podとして実行されます。PySparkアプリ(Pythonで実装したSparkアプリ)の処理終了後、自動的にPodが終了します(Spark v3.1.2で確認済み)。
Podが終了することで、PySparkアプリ(Pythonで実装したSparkアプリ)でPod内に作成した集計結果などを記載したファイルを閲覧できなくなります。(下図参照)

上記の問題を解決する方法として、「SparkでKubernetesの永続ボリューム(PV/PVC)の利用」があります。下図のように「Kubernetes上で実行したPySparkアプリ(Pythonで実装したSparkアプリ)で作成したファイルをPod終了後でも参照可能」となります。

以上が、「SparkでKubernetesの永続ボリューム(PV/PVC)を使う利点」となります。
PySparkアプリ(Pythonで実装したSparkアプリ)で作成したファイルなどを後からでも参照したい場合、Kubernetesの永続ボリューム(PV/PVC)を利用しましょう。
Spark on Kubernetesで永続ボリューム(PV/PVC)を使う為の準備

「Spark on Kubernetesで永続ボリューム(PV/PVC)を使う為の準備」に関してご紹介します。
★Spark on Kubernetesで永続ボリューム(PV/PVC)を使う為の準備の流れ★
手順1:Kubernetesクラスタを構築
手順2:構築したKubernetesクラスタの状態確認
手順3:Kubernetesで永続ボリューム(PV/PVC)を作成
上記の流れで、「Spark on Kubernetesで永続ボリューム(PV/PVC)を使う為の準備」ができます。
上記の各手順は、以下の日時と環境で動作確認済みです。
動作確認済み日時:2021年7月28日
動作確認済み環境:CentOS Linux release 7.7.1908 (Core)
以降で、上記「Spark on Kubernetesで永続ボリューム(PV/PVC)を使う為の準備の流れ」の各手順に関してご説明します。
手順1:Kubernetesクラスタを構築
「手順1:Kubernetesクラスタを構築」に関してご説明します。
PySparkアプリ(Pythonで実装したSparkアプリ)でKubernetesの永続ボリューム(PV/PVC)を使うために、Kubernetesクラスタを構築しましょう。
「Kubernetesクラスタの構築手順」に関しては、以下の記事をご覧ください。

上記手順を実施することで、以下のKubernetesクラスタを構築できます。
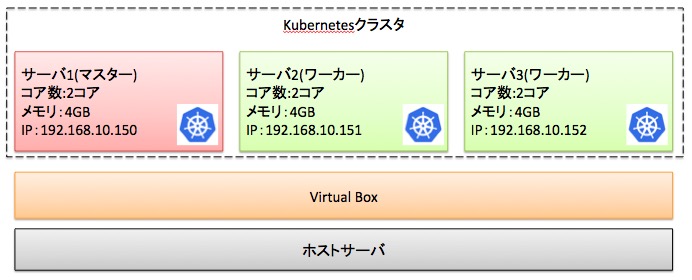
以降の手順では、上図のKubernetesクラスタを想定として手順を解説します。
既にKubernetesクラスタを構築済みである場合、本手順を省略してください。
以上で、「手順1:Kubernetesクラスタを構築」は完了です。
手順2:構築したKubernetesクラスタの状態確認
「手順2:構築したKubernetesクラスタの状態確認」に関してご説明します。
構築したKubernetesクラスタで、永続ボリューム(PV/PVC)を使用したPySparkアプリを実行できる状態になっているかを確認しましょう。
「構築したKubernetesクラスタの状態確認」に関しては、以下の記事「手順2:構築したKubernetesクラスタの状態確認」をご覧ください。
以上で、「手順2:構築したKubernetesクラスタの状態確認」は完了です。
手順3:Kubernetesで永続ボリューム(PV/PVC)を作成
「手順3:Kubernetesで永続ボリューム(PV/PVC)を作成」に関してご説明します。
PySparkアプリ(Pythonで実装したSparkアプリ)で利用したいKubernetesの永続ボリューム(PV/PVC)を作成しましょう。
「Kubernetesの永続ボリューム(PV/PVC)の作成手順」に関しては、以下の記事をご覧ください。

以上で、「手順3:Kubernetesで永続ボリューム(PV/PVC)を作成」は完了です。
上記の流れで、Spark on Kubernetesで永続ボリューム(PV/PVC)を使う為の準備ができました。
Spark on Kubernetesで永続ボリューム(PV/PVC)を使う手順

「Spark on Kubernetesで永続ボリューム(PV/PVC)を使う手順」に関してご紹介します。
★Spark on Kubernetesで永続ボリューム(PV/PVC)を使う流れ★
手順1:PySparkアプリ(Pythonで実装したSparkアプリ)を実装
手順2:実装したPySparkアプリをKubernetesで実行
手順3:Kubernetes上で実行したPySparkアプリの動作結果を確認
上記手順を実施することで、下図のように「PySparkアプリのPod終了後でも作成したファイルを参照」できます。
上記の各手順は、以下の日時と環境で動作確認済みです。
動作確認済み日時:2021年7月28日
動作確認済み環境:CentOS Linux release 7.7.1908 (Core)
以降で、上記「Spark on Kubernetesで永続ボリューム(PV/PVC)を使う流れ」の各手順に関してご説明します。
手順1:PySparkアプリ(Pythonで実装したSparkアプリ)を実装
「手順1:PySparkアプリ(Pythonで実装したSparkアプリ)を実装」に関してご説明します。
Kubernetes上で実行したいPySparkアプリを作成しましょう。
処理結果をファイルへ保存するPySparkアプリ(Pythonで実装したSparkアプリ)のプログラムは、以下となります。
#!/usr/bin/env python
# coding:utf-8
## 処理結果をファイルへ出力するsparkアプリケーション
from pyspark import SparkContext
import sys
# 1. 引数を変数に格納
args = sys.argv
output_dir = args[1] # 引数から処理結果を書き出すファイルのPATHを設定
## 2. sparkの設定を作成
sc = SparkContext("local", "count app")
words = sc.parallelize (
[
"python",
"kubernetes"]
)
## 3. ファイルへ出力
words.saveAsTextFile(output_dir)
上記PySparkのプログラムを「pyspark-output-file.py」というファイル名で保存しましょう。保存後、下記記事の「PySpark(PythonのSparkアプリ)をKubernetes上で実行する手順」を参照し、コンテナ化してください。

以上で、「手順1:PySparkアプリ(Pythonで実装したSparkアプリ)を実装」は完了です。
手順2:実装したPySparkアプリをKubernetesで実行
「手順2:実装したPySparkアプリをKubernetesで実行」に関してご説明します。
手順2で作成した「PySparkアプリ(Pythonで実装したSparkアプリ)」を実行しましょう。
作成した「処理結果をファイルへ保存するPySparkアプリ(Pythonで実装したSparkアプリ)」を以下のコマンドで実行しましょう。
[root@node1 spark-3.1.2-bin-hadoop3.2]# bin/spark-submit \
--master k8s://https://127.0.0.1:6443 \
--deploy-mode cluster \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=spark1 \
--conf spark.kubernetes.container.image=herokakedashi/spark-py:spark-p-hadoop \
--name spark-python-app \
--conf spark.kubernetes.driver.volumes.persistentVolumeClaim.volume.mount.path=/mnt/ \
--conf spark.kubernetes.driver.volumes.persistentVolumeClaim.volume.mount.readOnly=false \
--conf spark.kubernetes.driver.volumes.persistentVolumeClaim.volume.options.claimName=nfs-pvc \
--conf spark.kubernetes.executor.volumes.persistentVolumeClaim.volume.mount.path=/mnt/ \
--conf spark.kubernetes.executor.volumes.persistentVolumeClaim.volume.mount.readOnly=false \
--conf spark.kubernetes.executor.volumes.persistentVolumeClaim.volume.options.claimName=nfs-pvc \
local:///app/pyspark-output-file.py "/mnt/output"
コマンドの詳細情報に関しては、以下のApache Spark公式ページをご覧ください。
SparkでKubernetesの永続ボリューム(PV/PVC)を利用する方法
以上で、「手順2:実装したPySparkアプリをKubernetesで実行」は完了です。
手順3:Kubernetes上で実行したPySparkアプリの動作結果を確認
「手順3:Kubernetes上で実行したPySparkアプリの動作結果を確認」に関してご説明します。
実行したPySparkアプリ(Pythonで実装したSparkアプリ)の実行結果を確認してみましょう。
「PySparkアプリ(Pythonで実装したSparkアプリ)」の実行結果を確認するために、以下のコマンドをマスターで実行してください。
# cat /nfs_dir/output/part-00000
python
kubernetes
#
上記の確認ができた場合、正常に「処理結果をファイルへ保存するPySparkアプリ(Pythonで実装したSparkアプリ)を実行できた」と判断できます。
以上で、「手順3:Kubernetes上で実行したPySparkアプリの動作結果を確認」は完了です。
上記の流れで、「Spark on Kubernetesで永続ボリューム(PV/PVC)を使う」ことができました。
ちなみに、「Apache Sparkのアーキテクチャを体系的に学びたい」や「Apache Sparkの特徴を知りたい」方は、以下の参考書がオススメです。
動画で学びたいという方には、以下がオススメです。
【まとめ】Spark on Kubernetesで永続ボリューム(PV/PVC)を使う手順

今回の記事を通して、「Spark on Kubernetesで永続ボリューム(PV/PVC)を使う手順」をご紹介することで、以下の悩みを解消しました。
★悩み★
・SparkでKubernetesの永続ボリューム(PV/PVC)を使う手順を知りたいな。
・PySpark(Python on Spark)でKubernetesの永続ボリュームを使いたい。
・Apache SparkでKubernetesの「永続ボリューム(PV/PVC)」を使う利点は?
「SparkでKubernetesの永続ボリューム(PV/PVC)を使う手順は?」や「PySparkでKubernetesの永続ボリューム(PV/PVC)を利用する手順は?」で悩んでいるあなたにこの記事が少しでも役に立てれば幸いです。


コメント