
【悩み】
・PythonでWord内に記載されたテキストを抽出したい。
・Word内に挿入されたコメントを抽出したい。
・Wordからテキスト抽出するPythonプログラムを作りたい。
こういった「悩み」に答えます。
【本記事の内容】
① Wordからテキスト抽出できるPythonライブラリ
➁ 事前準備:各種インストールとWordの構造理解
➂ PythonでWordからテキストを抽出:3つの事例
本記事に掲載した方法を実践したことで、Pythonを使ってWord文書(docxやdocファイル)からテキスト(コメントのテキストも)を抽出できました(下の動画参照)。
記事の前半では「Wordからテキスト抽出するために使えるPythonライブラリの一覧」について解説します。
記事の後半では「ライブラリのインストール方法などの環境準備」と「Wordからテキストを抽出するPythonプログラム」を説明します。
この記事を読み終えることで、「Wordファイルを開かずに特定文字が記載されているかを判断できる」状態になります。
ちなみに、「新規作成」「編集」「変換」といった操作もPythonで実施できます。以下の記事にまとめているので興味がある方は是非ご覧ください。

Wordからテキスト抽出できるPythonライブラリ

PythonでWordからテキストを抽出したい場合、「python-docx」や「Aspose.Words」ライブラリを使います。
以下の記事で各ライブラリのライセンスや概要をご紹介しています。気になる方は、ぜひ読んでみてください。
>>【5分でわかる】PythonでWordを新規作成する方法
以降で、Wordからテキスト抽出するための環境準備を説明します。Pythonやライブラリのインストール手順を丁寧に解説しますね。
事前準備:各種インストールとWordの構造理解

「PythonでWordからテキスト抽出するための準備」に関してご紹介します。
【流れ】
手順1:Pythonのインストール
手順2:python-docxのインストール
手順3:Aspose.Wordsのインストール
手順4:lxmlのインストール
手順5:Word文書のオブジェクト構造
上記の流れで説明します。
Pythonのインストール
以下の記事を参考にし、お使いのパソコンやサーバーにPythonをインストールしましょう。
>> 【ubuntu向け】pyenvでPythonをインストールする手順【簡単】
>> 【コピペOK】pyenvでPythonをインストールする手順【Linux用】
>> 【最短5分】PyAutoGUIをWindowsにインストールする手順の「手順1:Pythonのインストール」を参照
>> 【環境構築】インストーラーでMacOSにPythonをインストール
python-docxのインストール
python-docxライブラリのインストール手順に関しては、以下の記事の「python-docxとbayoo-docxのインストール」箇所をご覧ください。
>>【5分でわかる】PythonでWordを新規作成する方法
Aspose.Wordsのインストール
本記事公開時点のpython-docxライブラリには、「コメント抽出」機能は存在しないです。そのため、コメントを抽出したい場合、Aspose.Wordsライブラリを使う必要があります。
以下のコマンド実行により、Aspose.Wordsライブラリをインストールできます。
pip install aspose-words
pip list
コマンド実行後、「aspose-words(バージョン)」が表示された場合、「正常にライブラリをインストールできた」と判断できます。
lxmlのインストール
本記事公開時点のpython-docxライブラリには、「コメント抽出」機能は存在しないです。そのため、コメントを抽出したい場合、lxmlライブラリを使って自作が必要です。
lxmlライブラリのインストール手順に関しては、以下の記事の「ステップ2」箇所をご覧ください。
>> PythonでGoogle検索する方法【BeautifulSoup】
Word文書のオブジェクト構造
Word文書は、以下のWordprocessingML(略称:WML)という言語で作成されます。WMLの構造を把握しておくことで、Pythonで細かいWord操作を実現できます。
WMLの詳細に関しては、以下の記事の「Word文書のオブジェクト構造」箇所をご覧ください。
>>【5分でわかる】PythonでWordを新規作成する方法
また、本記事では、Word内のコメント抽出プログラムも説明します。
以下の図に、WMLのコメント関係のオブジェクト構造をまとめました。以下の図を押さえておくことで、プログラムの理解スピードが向上します。
ちなみに、以下の図は、「Microsoftのリファレンス」と「WMLのドキュメント」を確認し作成しました。
>> コメントのオブジェクト構造(Microsoftのリファレンス)
>> Paragraphsオブジェクトの構造(WMLのドキュメント)
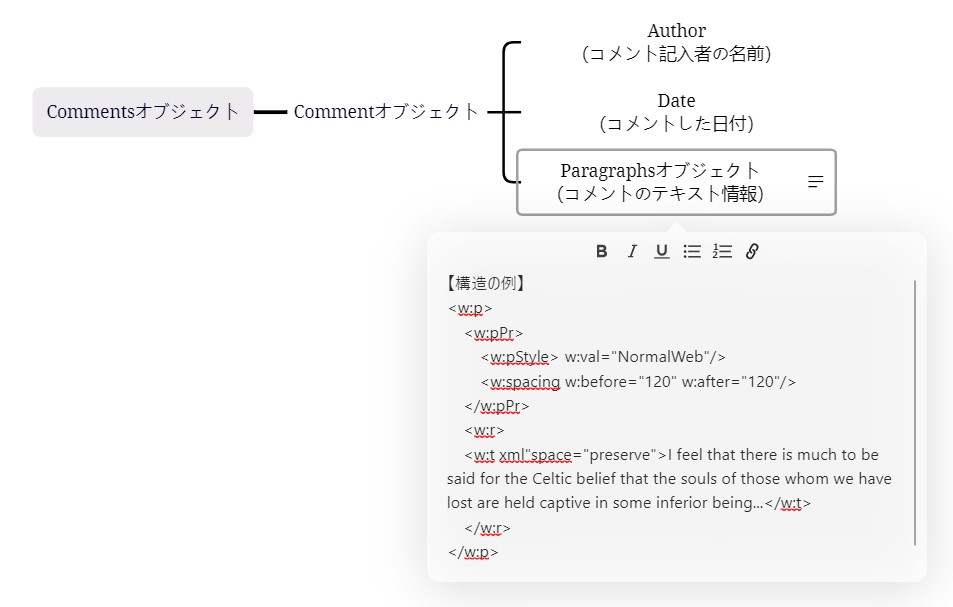
以降で、Pythonを使ってWordからテキストを抽出するプログラムとその実行結果を解説します。
PythonでWordからテキストを抽出:3つの事例

「PythonでWordからテキストを抽出する方法」に関してご紹介します。
【ご紹介事項】
・テキストを抽出:paragraphs変数
・コメント内のテキストのみを抽出:as_comment関数/xpath関数
・応用例:Word内で特定文字をテキスト検索
以降で、以下「sample.docx」のWordファイルを用いて、上記の各項目に関して説明します。
テキストを抽出:paragraphs変数
「Wordからテキストを抽出する」プログラムは、以下となります。
import docx
word_path = './sample.docx'
#指定したワードファイルを読み込む
doc = docx.Document(word_path)
#ワードに記載されたテキストを出力する
for p in doc.paragraphs:
print(p.text)
上記のプログラムを「extract-text.py」というファイル名で保存しましょう。
【paragraphsについて】
・変数の意味
Wordの段落内に記載されたテキストがリスト形式で格納されている
・使い方
Document型の変数.paragraphs
・補足
for文などの繰り返し構文を使うことで格納された全ての情報を出力できる
・参照
paragraphsのリファレンス(公式サイト)
以下のコマンドで、上記プログラムを実行できます。
python extract-text.py
その結果、以下のようにWordからテキストを抽出できます(下の動画参照)。
コメント内のテキストのみを抽出:as_comment関数/xpath関数
「Wordに挿入されたコメント内のテキストを抽出する」プログラムの実現方法は2つあります。
1つ目の実現方法は、以下のようにAspose.Wordsライブラリを使う方法です。
import aspose.words as aw
#コメントのテキスト抽出関数
def extract_comments(doc) :
collectedComments = []
comments = doc.get_child_nodes(aw.NodeType.COMMENT, True)
for node in comments :
#コメントを取得
comment = node.as_comment()
#コメントの情報を変数に格納
collectedComments.append(comment.author + " " + comment.date_time.strftime("%Y-%m-%d %H:%M:%S") + " " + comment.to_string(aw.SaveFormat.TEXT))
return collectedComments
word_file_path = './sample.docx'
#ワードファイルを読み込む
doc = aw.Document(word_file_path)
#抽出したコメントのテキストを表示
print(extract_comments(doc))
上記プログラムに関しては、以下のAspose.Words公式サイトに掲載されています。
参照:Aspose.Wordsライブラリを使ったコメント抽出(公式サイト)
【get_child_nodes関数とas_comment関数について】
・機能
Word内に記載されたコメント情報を取得する
・使い方
list = Document型変数.get_child_nodes(aw.NodeType.COMMENT, True):
for node in list:
comment = node.as_comment()
・補足
python-docxではコメント抽出機能はないため、Aspose.Wordsを使う
・参照
get_child_nodes関連のリファレンス(公式サイト)
2つ目の実現方法は、以下のようにlxmlライブラリを使う方法です。
from lxml import etree
import zipfile
#コメント内のテキストを抽出し表示する関数
def get_comments(docxFileName):
#XMLタグのメタ情報を定義
ooXMLns = {'w':'http://schemas.openxmlformats.org/wordprocessingml/2006/main'}
#コメントが記載されているXMLファイルの読み込み
docxZip = zipfile.ZipFile(docxFileName)
commentsXML = docxZip.read('word/comments.xml')
et = etree.XML(commentsXML)
#コメントが記載されたXMLタグを抽出
comments = et.xpath('//w:comment',namespaces=ooXMLns)
for c in comments:
# 記入者情報を取得
print(c.xpath('@w:author',namespaces=ooXMLns))
# 日付情報を取得
print(c.xpath('@w:date',namespaces=ooXMLns))
# 挿入されたコメントを取得
comment_text = ''
for w_p in c.xpath('./w:p',namespaces=ooXMLns):
for w_r in w_p.xpath('./w:r',namespaces=ooXMLns):
for w_t in w_r.xpath('./w:t',namespaces=ooXMLns):
comment_text += w_t.text
comment_text += '\r\n'
print(repr(comment_text))
word_file_path = './sample.docx'
#コメントを抽出し表示
get_comments(word_file_path)
上記プログラムに関しては、以下のstack overflowに掲載されたプログラムをもとにして作成しました。
参照:Extract DOCX Comments(stack overflowのサイト)
【xpath関数について】
・機能
指定したタグを取得する
・使い方
etree.XML型の変数.xpath(‘タグ名’,namespaces=’タグの属性’)
・補足
python-docxではコメント抽出機能はないため、lxmlで自作する
・参照
xpath関数のリファレンス(公式サイト)
上記の2つのプログラムを「extract-comment-text-aspose.py」と「extract-comment-text-lxml.py」というファイル名で保存しましょう。
以下のコマンドで、上記プログラムを実行できます。
python extract-comment-text-aspose.py
python extract-comment-text-lxml.py
その結果、以下のようにWordからコメントを抽出できます(下の動画参照)。
応用例:Word内で特定文字をテキスト検索
今まで紹介したプログラムの応用例として、「Word内で特定文字の検索」が考えられます。「Word内で特定文字の検索」プログラムは、以下となります。
import docx
from lxml import etree
import zipfile
#検索したい単語
keyword = 'コメント'
#検索対象のワードファイル
word_path = './sample.docx'
#ワードファイルの読み込み
doc = docx.Document(word_path)
#段落内のテキストを検索
for para in doc.paragraphs:
#単語が含まれている場合に表示
if keyword in para.text:
print(para.text)
#コメント内のテキストを検索
ooXMLns = {'w':'http://schemas.openxmlformats.org/wordprocessingml/2006/main'}
docxZip = zipfile.ZipFile(word_path)
commentsXML = docxZip.read('word/comments.xml')
et = etree.XML(commentsXML)
comments = et.xpath('//w:comment',namespaces=ooXMLns)
for c in comments:
# 挿入されたコメント
comment_text = ''
for w_p in c.xpath('./w:p',namespaces=ooXMLns):
for w_r in w_p.xpath('./w:r',namespaces=ooXMLns):
for w_t in w_r.xpath('./w:t',namespaces=ooXMLns):
comment_text += w_t.text
comment_text += '\r\n'
#単語が含まれている場合に表示
if keyword in comment_text:
print(comment_text)
上記のプログラムを「search-word.py」というファイル名で保存しましょう。
以下のコマンドで、上記プログラムを実行できます。
python search-word.py
その結果、以下のように指定したWordファイル内に特定文字があるかどうかを確認できます(下の動画参照)。
上記のようにpython-docx、aspose.words、lxmlライブラリを使うことで、Wordからテキストを抽出できます。
Pythonを使うことで、Word文書からテキストを抽出できることを説明しました。このPythonを使うことで、あらゆる業務や作業を自動化できます。
その事例やヒントを知りたい方には、以下の本がオススメです。
ちなみに、上記教材の詳細なレビューに関しては、以下のサイトにまとめています。
>> 「退屈なことはPythonにやらせよう」のレビューの一覧
【まとめ】3つのライブラリでWordからテキスト抽出が可能

いかがでしたでしょうか?
上記で紹介したpython-docx、Aspose.Words、lxmlライブラリを使うことで、PythonでWord文書からテキストを抽出できます。
最後にもう一度内容を確認しましょう。
【おさらい】
・PythonでWordからテキスト抽出する場合、3つのライブラリから選ぶこと
・コメントを抽出したい場合はAspose.Wordsかlxmlを使うこと
・テキスト抽出の応用例として、「Word内で特定文字を検索」がある
ちなみに、「新規作成」「編集」「変換」といった操作もPythonで実施できます。以下の記事にまとめているので興味がある方は是非ご覧ください。
本ブログでは、「業務の時短化に繋がるIT技術」や「クラウドやOSSの学び方」などを発信しています。定期的に更新していますので、ぜひブックマークをよろしくお願いいたします。


コメント