

★悩み★
・Kubernetes上でApache Sparkのアプリケーションを実行できるのかな。
・Kubernetes上でApache SparkのPIアプリケーションを実行したいな。
・KubernetesでApache Sparkのクラスタを構築する手順を知りたい。
こういった「悩み」に答えます。
★本記事の内容★
① KubernetesでApache Sparkのクラスタを構築する手順をご紹介
② Kubernetes上のApache SparkクラスタでPiアプリを実行する手順をご紹介
これからご紹介する「【Pi実行】KubernetesでApache Sparkクラスタを構築する手順」を実践したことで、3時間以内で「Apache Sparkのサンプルアプリ(Piアプリ)をKubernetes上に構築したApache Sparkのクラスタで実行」できました。
記事の前半では「KubernetesでApache Sparkのクラスタを構築する手順」を解説します。
記事の後半では「Kubernetes上のApache SparkクラスタでPiアプリを実行する手順」を紹介します。
この記事を読み終えることで、「Kubernetes上にApache Sparkクラスタを構築できる」や「Kubernetes上でApache Sparkのサンプルアプリ(Piアプリ)を実行できる」状態になります。
★Kubernetesとは★
Kubernetesを利用することで、マイクロサービスなシステムを構築できます。Kubernetesを利用したマイクロサービスに関して知りたい方は、以下の記事をご覧ください。
Kubernetesとマイクロサービスについて
ちなみに、Pythonで実装したSparkアプリケーションをKubernetes上で実行する手順に関して知りたい方は、以下の記事をご覧ください。

ちなみに、「Kubernetesを体系的に学習したい」方には、以下の記事がお勧めです。

KubernetesでApache Sparkのクラスタを構築する手順

「KubernetesでApache Sparkのクラスタを構築する手順」に関してご紹介します。
★KubernetesでApache Sparkのクラスタを構築する手順の流れ★
手順1:Kubernetesクラスタを構築(Apache Sparkクラスタの構築)
手順2:構築したKubernetesクラスタ(Apache Sparkクラスタ)の状態確認
上記の流れで、「KubernetesでApache Sparkのクラスタを構築」できます。
上記の各手順は、以下の日時と環境で動作確認済みです。
動作確認済み日時:2021年6月21日
動作確認済み環境:CentOS Linux release 7.7.1908 (Core)
以降で、上記「KubernetesでApache Sparkのクラスタを構築する手順の流れ」の各手順に関してご説明します。
手順1:Kubernetesクラスタを構築(Apache Sparkクラスタの構築)
「手順1:Kubernetesクラスタを構築(Apache Sparkクラスタの構築)」に関してご説明します。
Kubernetes上でApache Sparkのアプリケーションを実行するために、Kubernetesクラスタを構築しましょう。
構築したKubernetesクラスタをそのままApache Sparkのクラスタとして利用できます。
「Kubernetesクラスタの構築手順」に関しては、以下の記事をご覧ください。

上記手順を実施することで、以下のKubernetesクラスタ(Apache Sparkクラスタ)を構築できます。
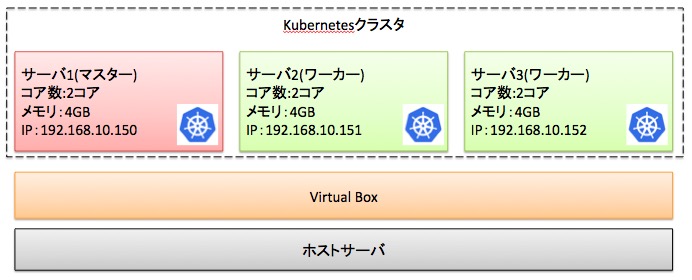
以降の手順では、上図のKubernetesクラスタを想定として手順を解説します。
既にKubernetesクラスタを構築済みである場合、本手順を省略してください。
以上で、「手順1:Kubernetesクラスタを構築(Apache Sparkクラスタの構築)」は完了です。
手順2:構築したKubernetesクラスタ(Apache Sparkクラスタ)の状態確認
「手順2:構築したKubernetesクラスタ(Apache Sparkクラスタ)の状態確認」に関してご説明します。
構築したKubernetesにおいて、Apache Sparkのアプリケーションを実行できる状態になっているかを確認しましょう。
「構築したKubernetesクラスタの状態確認」に関しては、以下の記事「手順2:構築したKubernetesクラスタの状態確認」をご覧ください。

以上で、「手順2:構築したKubernetesクラスタの状態確認」は完了です。
上記の流れで、KubernetesでApache Sparkのクラスタを構築できました。
Kubernetes上のApache SparkクラスタでPiアプリを実行する手順

「Kubernetes上のApache SparkクラスタでPiアプリを実行する手順」に関してご紹介します。
★Kubernetes上のApache SparkクラスタでPiアプリを実行する流れ★
手順1:Apache Sparkをダウンロード
手順2:DockerHubのアカウント(ID)を作成(SignUp)
手順3:Apache Sparkのコンテナイメージを作成
手順4:作成したApache SparkのコンテナイメージをDockerHubへ登録
手順5:作成したApache SparkのコンテナイメージをKubernetesで実行
手順6:Kubernetes上で実行したApache Sparkの動作結果を確認
上記手順を実施することで、Kubernetes上でApache Sparkのサンプルアプリケーション(Piアプリ)を実行できます。
上記の各手順は、以下の日時と環境で動作確認済みです。
動作確認済み日時:2021年6月21日
動作確認済み環境:CentOS Linux release 7.7.1908 (Core)
以降で、上記「Kubernetes上のApache SparkクラスタでPiアプリを実行する流れ」の各手順に関してご説明します。
手順1:Apache Sparkをダウンロード【k8sで動く媒体を取得】
「手順1:Apache Sparkをダウンロード」に関してご説明します。
Kubernetes上で動作するApache Sparkの媒体をダウンロードして解凍しましょう。
Apache Sparkの媒体をダウンロードするために、マスターで「端末」または「コマンドプロンプト」を起動し、以下のコマンドを実行しましょう。
# wget https://ftp.jaist.ac.jp/pub/apache/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz
# ls
spark-3.1.2-bin-hadoop3.2.tgz
コマンド実行後、「spark-3.1.2-bin-hadoop3.2.tgz」が表示された場合、「正常にApache Sparkの媒体をダウンロードできた」と判断できます。その後、「spark-3.1.2-bin-hadoop3.2.tgz」を任意の場所に解凍してください。
以上で、「手順1:Apache Sparkをダウンロード」は完了です。
手順2:DockerHubのアカウント(ID)を作成(SignUp)
「手順2:DockerHubのアカウント(ID)を作成(SignUp)」に関してご説明します。
Kubernetes上でApache Sparkを実行するためには、DockerHubのアカウント(ID)が必要です。
「DockerHubのアカウント(ID)を作成する(SignUp)手順」に関しては、以下の記事をご覧ください。

既にDockerHubのアカウント(ID)を持っている方は、本手順を省略してください。
以上で、「手順2:DockerHubのアカウント(ID)を作成(SignUp)」は完了です。
手順3:Apache Sparkのコンテナイメージを作成
「手順3:Apache Sparkのコンテナイメージを作成」に関してご説明します。
Kubernete上でApache Sparkを実行したい場合、Apache Sparkのコンテナイメージを作成しDockerHubに公開する必要があります。
Apache Sparkのコンテナイメージを作成するために、マスターで以下のコマンドを順に実行してください。
# cd spark-3.1.2-bin-hadoop3.2
# ls
LICENSE NOTICE R README.md RELEASE bin conf data examples jars kubernetes licenses python sbin yarn
# ↓ -r には、DockerHubのアカウント名(ID)を指定する ↓
# ↓ -t には、任意のタグ名を指定する ↓
# ./bin/docker-image-tool.sh -r herokakedashi -t spark-test-hadoop build
# echo $?
0
#
コマンド実行後、「0」が表示された場合、「正常にKubernetes上で起動するApache Sparkのコンテナイメージを作成できた」と判断できます。
docker-image-tool.shのリファレンスは、以下を参照してください。
docker-image-tool.shのコマンドリファレンス(公式サイト)
以上で、「手順3:Apache Sparkのコンテナイメージを作成」は完了です。
手順4:作成したApache SparkのコンテナイメージをDockerHubへ登録
「手順4:作成したApache SparkのコンテナイメージをDockerHubへ登録」に関してご説明します。
手順3で作成した「Apache Sparkのコンテナイメージ」をKubernetes上のApache Sparkクラスタで起動するために、DockerHubへ登録しましょう。
作成した「Apache Sparkのコンテナイメージ」をDockerHubへ登録するために、マスターで以下のコマンドを実行しましょう。
# cd spark-3.1.2-bin-hadoop3.2
# ↓ -rと-tには、buildコマンド実行時と同じ値を指定する ↓
# ./bin/docker-image-tool.sh -r herokakedashi -t spark-test-hadoop push
# echo $?
0
#
コマンド実行後、「0」が表示された場合、「作成したApache SparkのコンテナイメージをDockerHubへ正常に登録できた」と判断できます。
以上で、「手順4:作成したApache SparkのコンテナイメージをDockerHubへ登録」は完了です。
手順5:作成したApache SparkのコンテナイメージをKubernetesで実行
「手順5:作成したApache SparkのコンテナイメージをKubernetesで実行」に関してご説明します。
Kubernetes上のApache SparkクラスタでApache Sparkのサンプルアプリケーション(Piアプリ)を実行してみましょう。
Apache Sparkのサンプルアプリケーション「SparkPi(円周率を計算するアプリ)」をKubernetes上で実行するために、マスターで以下のコマンドを順に実行してください。
# kubectl create serviceaccount spark1
# kubectl create clusterrolebinding spark-role1 --clusterrole=edit --serviceaccount=default:spark1 --namespace=default
# cd spark-3.1.2-bin-hadoop3.2
# kubectl cluster-info
Kubernetes control plane is running at https://127.0.0.1:6443
# ↓ -masterには、kubectl cluster-infoで表示されたIPアドレスを指定する ↓
# ↓ serviceAccountNameには、kubectl create serviceaccountで作成した値を指定する ↓
# ↓ imageには、<buildコマンドの-rに指定した値>/spark:<buildコマンドの-tに指定した値>を指定する ↓
# bin/spark-submit \
--master k8s://https://127.0.0.1:6443 \
--deploy-mode cluster \
--conf spark.executor.instances=1 \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=spark1 \
--conf spark.kubernetes.container.image=herokakedashi/spark:spark-test-hadoop \
--class org.apache.spark.examples.SparkPi \
--name spark-pi \
local:///opt/spark/examples/jars/spark-examples_2.12-3.1.2.jar
# kubectl get po
NAME READY STATUS RESTARTS AGE
spark-pi-2efcca7a0fbc60ba-driver 0/1 Completed 0 40s
コマンド実行後、「Completed」と表示された場合、「作成したApache SparkのコンテナイメージをKubernetesで正常に実行できた」と判断できます。
以上で、「手順5:作成したApache SparkのコンテナイメージをKubernetesで実行」は完了です。
手順6:Kubernetes上で実行したApache Sparkの動作結果を確認
「手順6:Kubernetes上で実行したApache Sparkの動作結果を確認」に関しては、ご説明します。
Kubernetes上で実行したApache Sparkのサンプルアプリケーション「SparkPi(円周率を計算するアプリ)」の実行結果を確認してみましょう。
Kubernetes上で実行したApache Sparkのサンプルアプリケーション「SparkPi(円周率を計算するアプリ)」の実行結果を確認するために、以下のコマンドを実行してください。
# ↓ kubectl get poで表示されたPod名を指定する ↓
# kubectl logs spark-pi-2efcca7a0fbc60ba-driver
・
・
・
Pi is roughly 3.1468957344786723
・
・
・
#
コマンド実行後、「Pi is roughly」と表示された場合、「Kubernetes上で実行したApache Sparkのサンプルアプリケーションが正常に動作した」と判断できます。
以上で、「手順6:Kubernetes上で実行したApache Sparkの動作結果を確認」は完了です。
上記の流れで、「Kubernetes上のApache SparkクラスタでPiアプリを実行」できました。
ちなみに、「Apache Sparkのアーキテクチャを体系的に学びたい」や「Apache Sparkの特徴を知りたい」方は、以下の参考書がオススメです。
動画で学びたいという方には、以下がオススメです。
【まとめ】KubernetesでApache Sparkクラスタを構築する手順【Pi実行】

今回の記事を通して、「KubernetesでApache Sparkクラスタを構築する手順」と「Kubernetes上のApache SparkクラスタでPiアプリを実行する手順」をご紹介することで、以下の悩みを解消しました。
★悩み★
・Kubernetes上でApache Sparkのアプリケーションを実行できるのかな。
・Kubernetes上でApache SparkのPIアプリケーションを実行したいな。
・KubernetesでApache Sparkのクラスタを構築する手順を知りたい。
「KubernetesでApache Sparkを実行する手順は?」や「Kubernetes上でApache Sparkのクラスタを構築する手順は?」で悩んでいるあなたにこの記事が少しでも役に立てれば幸いです。

コメント