

★悩み★
・Kubernetesで動作する「PythonのSparkアプリ」を実装する手順は?
・Kubernetesで「Pythonで実装したSparkのアプリ」を実行できるのかな。
・KubernetesでPySpark(PythonのSparkアプリ)を実行する手順を知りたい。
こういった「悩み」に答えます。
★本記事の内容★
① PySpark(PythonのSparkアプリ)をKubernetesで実行する為の準備を紹介
② PySpark(PythonのSparkアプリ)をKubernetes上で実行する手順を紹介
これからご紹介する「KubernetesでPySpark(PythonのSparkアプリ)を実行する手順」を実践したことで、3時間以内で「Pythonで実装したSparkのアプリをKubernetes上で実行」できました。
記事の前半では「PySpark(PythonのSparkアプリ)をKubernetesで実行する為の準備」を解説しつつ、記事の後半では「PySpark(PythonのSparkアプリ)をKubernetes上で実行する手順」を紹介します。
この記事を読み終えることで、「Kubernetes上でPySparkを使える」状態になります。
★Kubernetesとは★
Kubernetesを利用することで、マイクロサービスなシステムを構築できます。Kubernetesを利用したマイクロサービスに関して知りたい方は、以下の記事をご覧ください。
Kubernetesとマイクロサービスについて
ちなみに、Javaで実装したSparkアプリケーションをKubernetes上で実行する手順に関して知りたい方は、以下の記事をご覧ください。

ちなみに、「Kubernetesを体系的に学習したい」方には、以下の記事がお勧めです。

PySpark(PythonのSparkアプリ)をKubernetesで実行する為の準備

「PySpark(PythonのSparkアプリ)をKubernetesで実行する為の準備」に関してご紹介します。
★PySparkをKubernetes上で実行するための準備の流れ★
手順1:Kubernetesクラスタを構築
手順2:構築したKubernetesクラスタの状態確認
上記の流れで、「PySpark(PythonのSparkアプリ)をKubernetes上で実行するための準備」ができます。
上記の各手順は、以下の日時と環境で動作確認済みです。
動作確認済み日時:2021年6月21日
動作確認済み環境:CentOS Linux release 7.7.1908 (Core)
以降で、上記「PySpark(PythonのSparkアプリ)をKubernetes上で実行するための準備の流れ」の各手順に関してご説明します。
手順1:Kubernetesクラスタを構築【PySparkの実行環境を用意】
「手順1:Kubernetesクラスタを構築」に関してご説明します。
Kubernetes上で「Pythonで実装したSparkのアプリ(PySpark)」を実行するために、Kubernetesクラスタを構築しましょう。
「Kubernetesクラスタの構築手順」に関しては、以下の記事をご覧ください。

上記手順を実施することで、以下のKubernetesクラスタを構築できます。
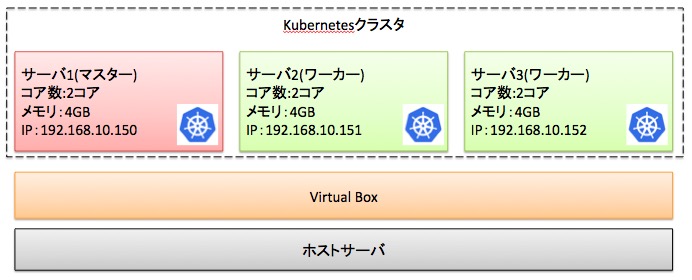
以降の手順では、上図のKubernetesクラスタを想定として手順を解説します。
既にKubernetesクラスタを構築済みである場合、本手順を省略してください。
以上で、「手順1:Kubernetesクラスタを構築」は完了です。
手順2:構築したKubernetesクラスタの状態確認
「手順2:構築したKubernetesクラスタの状態確認」に関してご説明します。
構築したKubernetesにおいて、Pythonで実装したSparkのアプリ(PySpark)を実行できる状態になっているかを確認しましょう。
「構築したKubernetesクラスタの状態確認」に関しては、以下の記事「手順2:構築したKubernetesクラスタの状態確認」をご覧ください。

以上で、「手順2:構築したKubernetesクラスタの状態確認」は完了です。
上記の流れで、KubernetesでPythonで実装したSparkのアプリ(PySpark)を実行するための準備ができました。
PySpark(PythonのSparkアプリ)をKubernetes上で実行する手順

「PySpark(PythonのSparkアプリ)をKubernetes上で実行する手順」に関してご紹介します。
★PySpark(PythonのSparkアプリ)をKubernetes上で実行するまでの流れ★
手順1:Apache Sparkをダウンロード
手順2:DockerHubのアカウント(ID)を作成(SignUp)
手順3:PythonでSparkアプリ(PySparkアプリ)を実装
手順4:実装したPySparkアプリを含むSparkのコンテナイメージを作成
手順5:PySparkアプリを含むSparkのコンテナイメージをDockerHubへ登録
手順6:PySparkアプリを含むSparkのコンテナイメージをKubernetesで実行
手順7:Kubernetes上で実行したPySparkアプリの動作結果を確認
上記手順を実施することで、Kubernetes上でPythonで実装したSparkのアプリ(PySpark)を実行できます。
上記の各手順は、以下の日時と環境で動作確認済みです。
動作確認済み日時:2021年6月21日
動作確認済み環境:CentOS Linux release 7.7.1908 (Core)
以降で、上記「PySpark(PythonのSparkアプリ)をKubernetes上で実行するまでの流れ」の各手順に関してご説明します。
手順1:Apache Sparkをダウンロード【コンテナ作成に必要】
「手順1:Apache Sparkをダウンロード」に関してご説明します。
PySparkアプリ(PythonのSparkアプリ)を同梱したApache Sparkのコンテナイメージを作成するために、Apache Sparkをダウンロードしましょう。
「Apache Sparkをダウンロードする手順」に関しては、以下の記事「手順1:Apache Sparkをダウンロード」をご覧ください。
以上で、「手順1:Apache Sparkをダウンロード」は完了です。
手順2:DockerHubのアカウント(ID)を作成(SignUp)
「手順2:DockerHubのアカウント(ID)を作成(SignUp)」に関してご説明します。
Kubernetes上でPySparkアプリ(Pythonで実装したSparkのアプリ)を実行するためには、DockerHubのアカウント(ID)が必要です。
「DockerHubのアカウント(ID)を作成する(SignUp)手順」に関しては、以下の記事をご覧ください。

既にDockerHubのアカウント(ID)を持っている方は、本手順を省略してください。
以上で、「手順2:DockerHubのアカウント(ID)を作成(SignUp)」は完了です。
手順3:PythonでSparkアプリ(PySparkアプリ)を実装
「手順3:PythonでSparkアプリ(PySparkアプリ)を実装」に関してご説明します。
Kubernetes上で実行したいPySparkアプリ(Pythonで実装したSparkのアプリ)を実装しましょう。
今回は、「単語を集計するPySparkアプリ(Pythonで実装したSparkのアプリ)」を実装しましょう。プログラムは、以下となります。
from pyspark import SparkContext
sc = SparkContext("local", "count app")
words = sc.parallelize (
[
"python",
"scala",
"java",
"hadoop",
"spark",
"dataframe",
"spark",
"pyspark",
"hadoop",
"pyspark",
"big data",
"ETL",
"jupyter"]
)
counts = words.count()
print(counts) # words変数に格納された単語の数を出力する。
上記のプログラムを「test.py」というファイル名で以下のディレクトリに保存しましょう。
# cd spark-3.1.2-bin-hadoop3.2
# ls ./kubernetes/dockerfiles/spark/bindings/python/test.py
test.py
以上で、「手順3:PythonでSparkアプリ(PySparkアプリ)を実装」は完了です。
手順4:実装したPySparkアプリを含むSparkのコンテナイメージを作成
「手順4:実装したPySparkアプリを含むSparkのコンテナイメージを作成」に関してご説明します。
Dockerfile編集後、PySparkアプリ(Pythonで実装したSparkアプリ)を同梱したSparkのコンテナイメージを作成しましょう。
Apache Sparkのコンテナイメージに実装したPySparkアプリ(PythonのSparkアプリ)を同梱するために、下記のDockerfileを編集してください。具体的には、下記の「ここから追加」から「ここまでを追加」をDockerfileに追記します。
# cd spark-3.1.2-bin-hadoop3.2
# cat ./kubernetes/dockerfiles/spark/bindings/python/Dockerfile
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
ARG base_img
FROM $base_img
WORKDIR /
# Reset to root to run installation tasks
USER 0
RUN mkdir ${SPARK_HOME}/python
RUN apt-get update && \
apt install -y python3 python3-pip && \
pip3 install --upgrade pip setuptools && \
# Removed the .cache to save space
rm -r /root/.cache && rm -rf /var/cache/apt/*
COPY python/pyspark ${SPARK_HOME}/python/pyspark
COPY python/lib ${SPARK_HOME}/python/lib
# ↓ ここから追加:作成したPySparkアプリ(Pythonで実装したSparkアプリ)をコンテナイメージにコピーする。 ↓
WORKDIR /app
COPY ./kubernetes/dockerfiles/spark/bindings/python/test.py .
# ↑ ここまでを追加 ↑
WORKDIR /opt/spark/work-dir
ENTRYPOINT [ "/opt/entrypoint.sh" ]
# Specify the User that the actual main process will run as
ARG spark_uid=185
USER ${spark_uid}
Dockerfile編集後、Pythonで実装したSparkアプリを含むSparkのコンテナイメージを作成するために、マスターで以下のコマンドを順に実行してください。
# cd spark-3.1.2-bin-hadoop3.2
# ls
LICENSE NOTICE R README.md RELEASE bin conf data examples jars kubernetes licenses python sbin yarn
# ↓ -r には、DockerHubのアカウント名(ID)を指定する ↓
# ↓ -t には、任意のタグ名を指定する ↓
# ./bin/docker-image-tool.sh -r herokakedashi -t spark-p-hadoop -p ./kubernetes/dockerfiles/spark/bindings/python/Dockerfile build
# docker images | grep spark-p
herokakedashi/spark-py spark-p-hadoop 80baf9d16e2d 36 seconds ago 910MB
#
コマンド実行後、「<DockerHubのアカウント名>/spark-py」が表示された場合、「正常にPythonで実装したSparkアプリを含むSparkのコンテナイメージを作成できた」と判断できます。
以上で、「手順4:実装したPySparkアプリを含むSparkのコンテナイメージを作成」は完了です。
手順5:PySparkアプリを含むSparkのコンテナイメージをDockerHubへ登録
「手順5:PySparkアプリを含むSparkのコンテナイメージをDockerHubへ登録」に関してご説明します。
手順4で作成した「Pythonで実装したSparkアプリを含むSparkのコンテナイメージ」をKubernetes上で起動するために、DockerHubへ登録しましょう。
作成した「Pythonで実装したSparkアプリを含むSparkのコンテナイメージ」をDockerHubへ登録するために、マスターで以下のコマンドを順に実行しましょう。
# cd spark-3.1.2-bin-hadoop3.2
# ↓ -rと-tには、buildコマンド実行時と同じ値を指定する ↓
# ./bin/docker-image-tool.sh -r herokakedashi -t spark-p-hadoop -p ./kubernetes/dockerfiles/spark/bindings/python/Dockerfile push
# echo $?
0
#
コマンド実行後、「0」が表示された場合、「正常にPythonで実装したSparkアプリを含むSparkのコンテナイメージをDockerHubに登録できた」と判断できます。
以上で、「手順5:PySparkアプリを含むSparkのコンテナイメージをDockerHubへ登録」は完了です。
手順6:PySparkアプリを含むSparkのコンテナイメージをKubernetesで実行
「手順6:PySparkアプリを含むSparkのコンテナイメージをKubernetesで実行」に関してご説明します。
Kubernetes上でPySparkアプリ(Pythonで実装したSparkアプリ)を実行してみましょう。
PySparkアプリ(Pythonで実装したSparkアプリ)をKubernetes上で実行するために、マスターで以下のコマンドを順に実行してください。
# kubectl create serviceaccount spark1
# kubectl create clusterrolebinding spark-role1 --clusterrole=edit --serviceaccount=default:spark1 --namespace=default
# cd spark-3.1.2-bin-hadoop3.2
# kubectl cluster-info
Kubernetes control plane is running at https://127.0.0.1:6443
# ↓ -masterには、kubectl cluster-infoで表示されたIPアドレスを指定する ↓
# ↓ serviceAccountNameには、kubectl create serviceaccountで作成した値を指定する ↓
# ↓ imageには、<buildコマンドの-rに指定した値>/spark:<buildコマンドの-tに指定した値>を指定する ↓
# ↓ 末尾には、実行したいPySparkアプリ(Pythonで実装したSparkアプリ)のコンテナ内でのファイルPathを指定する ↓
# bin/spark-submit \
--master k8s://https://127.0.0.1:6443 \
--deploy-mode cluster \
--conf spark.executor.instances=1 \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=spark1 \
--conf spark.kubernetes.container.image=herokakedashi/spark-py:spark-p-hadoop \
--name spark-python-app \
local:///app/test.py
# kubectl get po
NAME READY STATUS RESTARTS AGE
spark-python-app-bbfee87a189c7f8c-driver 0/1 Completed 0 61s
#
コマンド実行後、「Completed」と表示された場合、「PySparkアプリ(Pythonで実装したSparkアプリ)をKubernetes上で正常に実行できた」と判断できます。
以上で、「手順6:PySparkアプリを含むSparkのコンテナイメージをKubernetesで実行」は完了です。
手順7:Kubernetes上で実行したPySparkアプリの動作結果を確認
「手順7:Kubernetes上で実行したPySparkアプリの動作結果を確認」に関してご説明します。
Kubernetes上で実行したPySparkアプリ(Pythonで実装したSparkアプリ)の実行結果を確認してみましょう。
Kubernetes上で実行した「PySparkアプリ(Pythonで実装したSparkアプリ)」の実行結果を確認するために、マスターで以下のコマンドを実行してください。
# ↓ kubectl get poで表示されたPod名を指定する ↓
# kubectl logs spark-python-app-bbfee87a189c7f8c-driver
・
・
・
13
・
・
・
#
コマンド実行後、「13」と表示された場合、「Kubernetes上で実行したPySparkアプリ(Pythonで実装したSparkアプリ)が正常に動作した」と判断できます。
以上で、「手順7:Kubernetes上で実行したPySparkアプリの動作結果を確認」は完了です。
上記の流れで、PySpark(Pythonで実装したSparkアプリ)をKubernetes上で実行できました。
ちなみに、「Apache Sparkのアーキテクチャを体系的に学びたい」や「Apache Sparkの特徴を知りたい」方は、以下の参考書がオススメです。
動画で学びたいという方には、以下がオススメです。
【まとめ】KubernetesでPySpark(PythonのSparkアプリ)を実行する手順

今回の記事を通して、「KubernetesでPySpark(PythonのSparkアプリ)を実行する手順」をご紹介することで、以下の悩みを解消しました。
★悩み★
・Kubernetesで動作する「PythonのSparkアプリ」を実装する手順は?
・Kubernetesで「Pythonで実装したSparkのアプリ」を実行できるのかな。
・KubernetesでPySpark(PythonのSparkアプリ)を実行する手順を知りたい。
「KubernetesでPySpark(PythonのSparkアプリ)を実行する手順は?」で悩んでいるあなたにこの記事が少しでも役に立てれば幸いです。

コメント