
【悩み】
・Pythonのプログラムを実行したけど異常終了して動かない。
・UnicodeEncodeError: ‘cp932’ codec can’t encode character ‘\u2781’ in
position 54: illegal multibyte sequenceというエラーが出力されたけど何?
・UnicodeEncodeError: ‘cp932’ codecの原因と解消方法を知りたい。
こういった「悩み」に答えます。
【本記事の内容】
① UnicodeEncodeError: ‘cp932’ codec can’t encode characterの発生経緯
➁ UnicodeEncodeError: ‘cp932’ codec can’t encode characterの発生原因
➂ UnicodeEncodeError: ‘cp932’ codec can’t encode characterの解決方法
本記事を実践したことで、5分くらいで「UnicodeEncodeError: ‘cp932’ codec can’t encode character」のエラーを解決できました。
記事の前半では「2パターンの本エラー発生経緯」を解説します。
記事の後半では「本エラーの発生原因」から「解決方法」までを紹介します。
この記事を読み終えることで、「エラーで動かないPythonプログラムを解消でき、正常に動く状態」になるはずです。
UnicodeEncodeError: ‘cp932’ codec can’t encode characterの発生経緯

本エラーの発生経緯のパターンとして、以下があります。
【本エラー発生経緯のパターン】
・Pythonから文字などをファイルへ書き出した際に本エラーが発生
・Pythonで文字列をコマンドプロンプトへ出力した際に本エラーが発生
以降で、上記の各パターンに関して詳しく解説します。
Pythonから文字などをファイルへ書き出した際に本エラーが発生
筆者は、以下のようなPythonプログラムをWindows上で実行しようと考えていました。
import mammoth
# 対象のワードファイルのPATH
word_path = './sample.docx'
# 変換後のHTMLファイルのPATH
html_path = './output/sample.html'
# 対象のワードファイルを読み込みmarkdownファイルへ変換
with open(word_path, "rb") as docx_file:
result = mammoth.convert_to_html(docx_file)
# 変換した文字をファイルへ保存
with open(html_path, "w") as html_file:
html_file.write(result.value)
上記プログラムを「test.py」というファイル名で保存します。
上記プログラムは、ワードファイルに記載された文字を読み込み、変換後に文字をファイルへ保存するプログラムです。
保存したファイルを実行するために、以下のコマンドを実行したところ、「UnicodeEncodeError: ‘cp932’ codec can’t encode character」が発生しました。
python test.py
Traceback (most recent call last):
File "C:\Users\user\test.py", line 15, in <module>
html_file.write(result.value)
UnicodeEncodeError: 'cp932' codec can't encode character '\u2781' in position 54: illegal multibyte sequence
Pythonで文字列をコマンドプロンプトへ出力した際に本エラーが発生
筆者は、以下のようなPythonプログラムをWindows上で実行しようと考えていました。
import requests
from bs4 import BeautifulSoup
url = 'https://xxxx'
source=requests.get(url, headers=headers).text
soup = BeautifulSoup(source, 'lxml')
search_div = soup.find_all(class_='rc')
text = ''
for result in search_div:
・
・
・
抽出した情報をtextへ格納する処理
・
・
・
print(text)
上記プログラムを「test.py」というファイル名で保存します。
上記プログラムは、スクレイピングした結果から情報を抽出し、コマンドプロンプトに出力するプログラムです。
保存したファイルを実行したところ、「UnicodeEncodeError: ‘cp932’ codec can’t encode character」が発生しました。
以上が、「UnicodeEncodeError: ‘cp932’ codec can’t encode character の発生経緯」となります。
UnicodeEncodeError: ‘cp932’ codec can’t encode characterの発生原因

本事象の「発生原因」に関して解説します。
発生原因は、「Windowsが文字を自動的にCP932というエンコーディング(文字コード)に変換するから」です。
本事象の詳しい発生原因を以下に掲載します。
【発生原因】
エラーの意味:
「ある文字をCP932の文字コードに変換できません」です。
エラー箇所:
print関数やwrite関数を実行する際にエラーが発生
原因:
print関数やwrite関数で文字コード「CP932」に変換できない文字を
含んでいたため
補足:
WindowsではCP932という文字コードを採用しています。
そのため、ファイルや標準出力する際にCP932に自動変換されます。
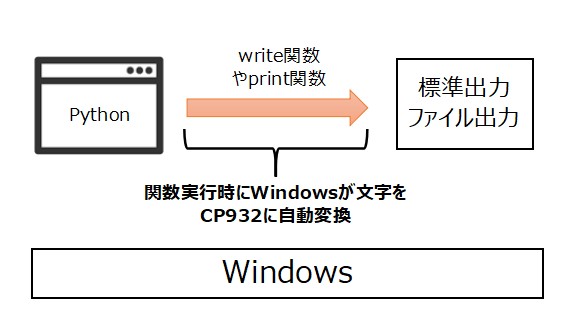
以上が、「UnicodeEncodeError: ‘cp932’ codec can’t encode characterの発生原因」となります。
Windowsが採用している文字コードのため本エラーが発生します。以降で、いくつかの解決方法を説明します。
UnicodeEncodeError: ‘cp932’ codec can’t encode characterの解決方法

本エラーの解決方法として、いくつかの方法があります。
【解決方法】
・ファイル入出力の場合:encoding=’utf-8’を指定
・CP932への変換に失敗した文字を削除
・CP932への変換に失敗した文字を無視
以降で、上記の各方法に関して詳しく解説します。
ファイル入出力の場合:encoding=’utf-8’を指定
write関数などのファイル入出力時に本エラーが発生した場合、以下のように「encoding=’utf-8’」を指定することで、本エラーを解消できます。
import mammoth
# 対象のワードファイルのPATH
word_path = './sample.docx'
# 変換後のHTMLファイルのPATH
html_path = './output/sample.html'
with open(word_path, "rb") as docx_file:
result = mammoth.convert_to_html(docx_file)
with open(html_path, "w", encoding='utf-8') as html_file:
html_file.write(result.value)
【open関数の構文】
・機能
指定したエンコーディングでファイルを開く
・使い方
open(ファイルPATH, モード, encoding=エンコーディング)
・参照
open関数のリファレンス(公式サイト)
CP932への変換に失敗した文字を削除
コマンドプロンプトへ出力した際に本エラーが発生した場合、以下のようなエラー内容が出力されます。
UnicodeEncodeError: 'cp932' codec can't encode character '\u2781' in position 54: illegal multibyte sequence
エラー内容に記載された文字を削除することで、本エラーを解消できます。上記エラーの場合、以下のreplace関数を使い「\u2781」を削除することで、本エラーを回避できます。
new_text = text.replace('\u2781', '')
print(new_text)
【replace関数の構文】
・機能
指定した文字を別の文字に置換する
・使い方
replace(置換したい文字, 置換後の文字)
・参照
replace関数のリファレンス(公式サイト)
CP932への変換に失敗した文字を無視
先ほど紹介したreplace関数で対処した場合、CP932に変換できない全ての文字を置換する必要があります。そのため、変数などに格納された文字において、CP932に変換できない文字を洗い出す必要があり非常に手間です。
そこで、以下のencode関数を使うことで、本エラーを容易に解消できます。
new_text = text.encode('cp932', 'replace')
print(new_text)
【encode関数の構文】
・機能
文字コードを変換する
・使い方
encode(変換したい文字コード, <任意:変換に失敗した際の処理>)
・補足
変換に失敗した際の処理として以下を指定できる
strict:変換できなかった場合エラーを発行する
ignore:変換できなかった文字を無視する
replace:変換できなかった文字を疑問符(?)に置換する
xmlcharrefreplace:変換不可な文字の前にXML文字参照を挿入する
backslashreplace:変換不可な文字の前にエスケープシーケンスを挿入する
・参照
encode関数のリファレンス(公式サイト)
以上のようにして、本事象を解消することができました。
【まとめ】本エラーの解決方法は3つある

いかがでしたでしょうか?
上記で紹介した「encoding=’utf-8’を指定」「CP932への変換に失敗した文字を削除」「CP932への変換に失敗した文字を無視」ことで、「UnicodeEncodeError: ‘cp932’ codec can’t encode characterのエラー」を解消できます。
最後にもう一度内容を確認しましょう。
【UnicodeEncodeError: ‘cp932’ codec can’tのエラーの原因と解決方法】
・原因
WindowsがCP932の文字コードに自動変換するため
・解決方法は3つ
1つ目:ファイル入出力の場合はencoding=’utf-8’を指定
2つ目:replace関数を使用
3つ目:encode関数を使用
本ブログでは、「業務の時短化に繋がるIT技術」や「クラウドやOSSの学び方」などを発信しています。定期的に更新していますので、ぜひブックマークをよろしくお願いいたします。
>> IT技術やその学び方を発信しているサイト「駆け出し物語」(本ブログ)


コメント